前回、JavaDiffUtils の基本動作を確認しました。
今回は簡易な実装で3-way-merge を行なっていきます。
3-way-merge 基本方針
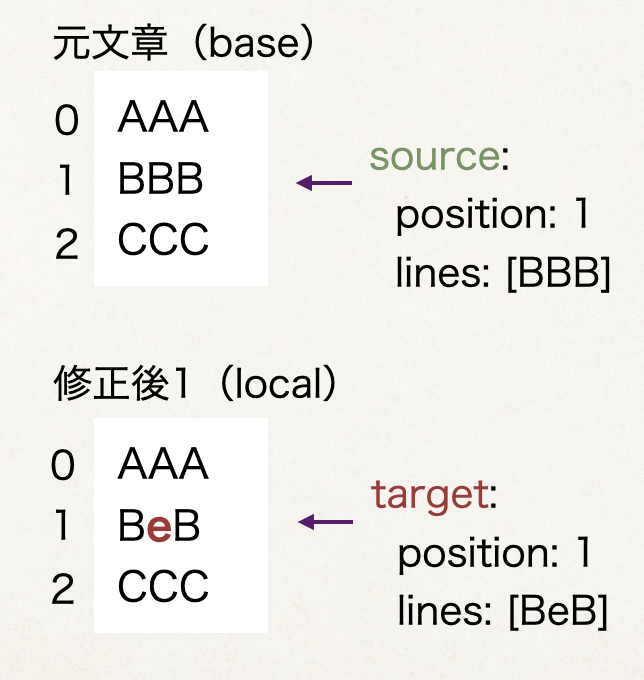
applyTo() は便利ですが、「両方の変更を残す」という要件は満たせません。そこで、source.lines とtarget.lines を使って、自前でマージを行います。
方針
- 修正なし –> base の行をそのまま採用
- 片方のみ修正 –> その修正版を採用
- 両方修正 –> 両方の修正を採用
実装例
kotlin
fun merge(base: List<String>, local: List<String>, remote: List<String>): List<String> {
val localPatch = DiffUtils.diff(base, local)
val remotePatch = DiffUtils.diff(base, remote)
// 元文章の何行目に関する修正かMap 型に変換しておく
// 適用済み管理と速度向上が目的なのでmutable
val localDeltasFirstPositionMap = localPatch.deltas.associateBy { it.source.position }.toMutableMap()
val remoteDeltasFirstPositionMap = remotePatch.deltas.associateBy { it.source.position }.toMutableMap()
val result = mutableListOf<String>()
var index = 0
// 文末に行を追加した場合、source.position がbase 最終行+1 となるので、base.size までループ
while (index <= base.size) {
val localDelta = localDeltasFirstPositionMap.remove(index)
val remoteDelta = remoteDeltasFirstPositionMap.remove(index)
when {
localDelta == null && remoteDelta == null -> {
// 修正なし
if (index < base.size) result += base[index]
index++
}
localDelta != null && remoteDelta == null -> {
// 片方修正(local)
result += localDelta.target.lines
index += localDelta.source.lines.size
}
localDelta == null && remoteDelta != null -> {
// 片方修正(remote)
result += remoteDelta.target.lines
index += remoteDelta.source.lines.size
}
else -> {
// 両方修正
result += localDelta!!.target.lines
result += remoteDelta!!.target.lines
index += localDelta.source.lines.size
}
}
}
return result
}動かすとこのようになります。
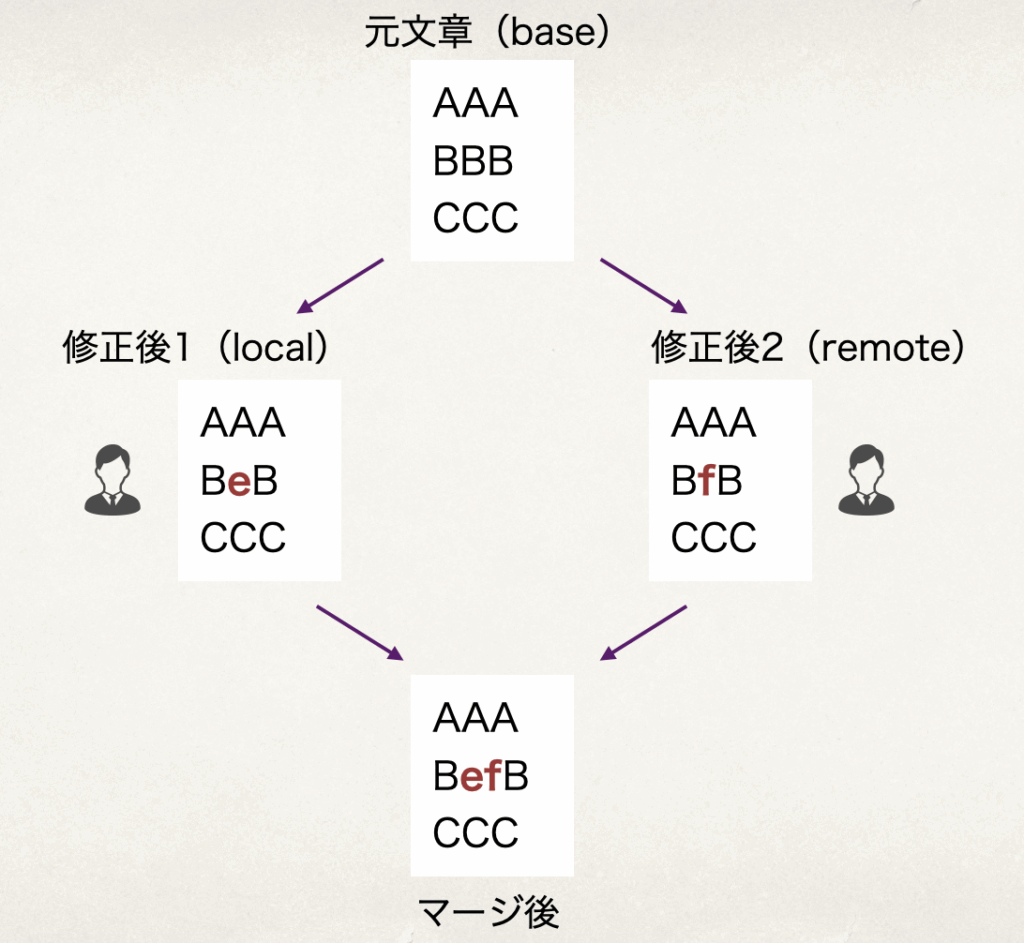
val base = listOf("AAA", "BBB", "CCC")
val local = listOf("AAA", "BeB", "CCC")
val remote = listOf("AAA", "BfB", "CCC")
val result = merge(base, local, remote)
result shouldBe listOf("AAA", "BeB", "BfB", "CCC")
AAA
BeB
BfB
CCC行単位でのマージはこれでバッチリです。
ですが、厳密にはコンフリクト時に問題があり、このロジックでは一部の文字が失われる可能性があります(詳細は次回説明します)。
一方で、コンフリクトが発生した行を文字単位に分解し、同じロジックを適用すれば目的の結果を得られそうです。
上のロジックのまま、文字単位でのマージを試してみます。
文字単位でマージ
2行目を文字単位で分解して、先ほどのロジックを適用してみます。
val base = listOf("B", "B", "B")
val local = listOf("B", "e", "B")
val remote = listOf("B", "f", "B")
val result = merge(base, local, remote)
result shouldBe listOf("B", "e", "f", "B")
BefB期待通りの結果が得られました。
行単位でマージを試みて、コンフリクトが発生した行は文字単位でマージを行う方針が良さそうです。
次回予告
コンフリクト時の問題についてお話しします。
【広告】