アクセスログをBigQuery に蓄積して解析したい、との要望があり、Java からBigQuery を操作する方法を調査・検証してみました。
手順としては以下のようになります。
プロジェクトの作成とBigQuery API の有効化
データセット作成
テーブル作成
サービスアカウント作成
Java からデータ挿入
1. プロジェクトの作成とBigQuery API の有効化
まずは Google Cloud Console にアクセスしてプロジェクトを作成します。
ご注意:クレジットカードを登録しておかないと、select 文を発行することができません。今回の検証範囲であれば無料枠内に収まります。
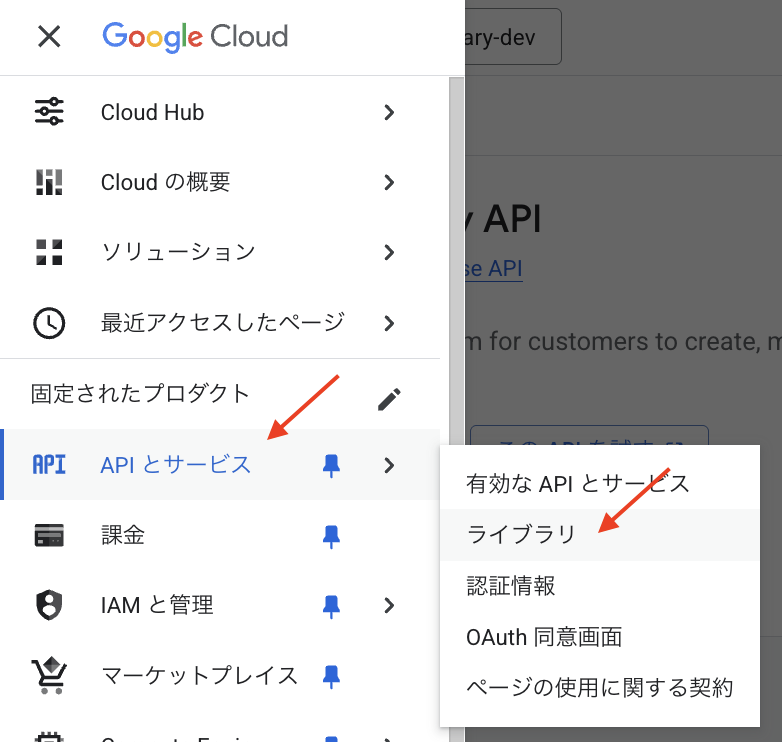
プロジェクト作成後、左側メニューから「API とサービス」>「ライブラリ」 を開きます。
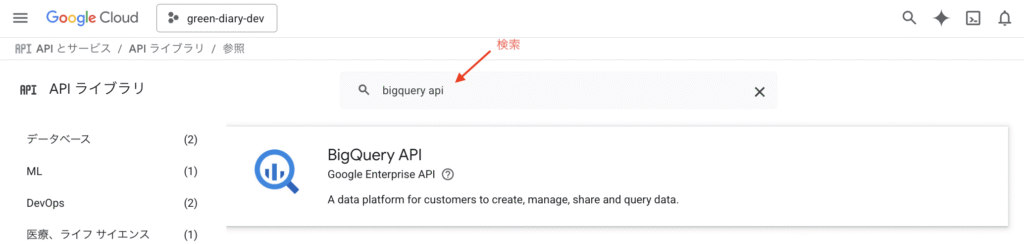
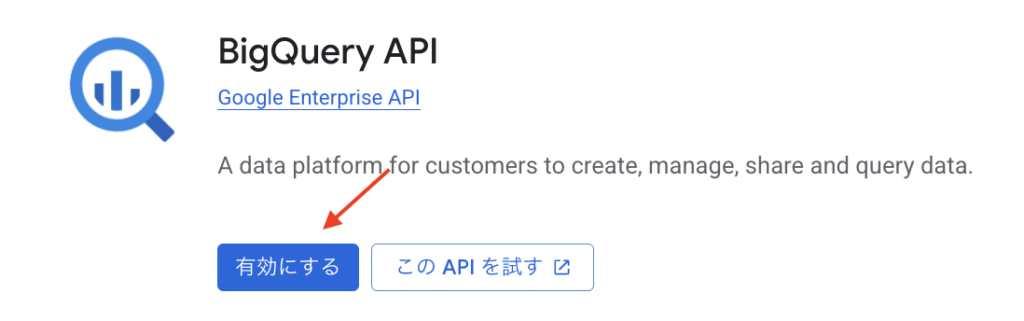
BigQuery API を検索します。
有効にします。
2. データセット作成
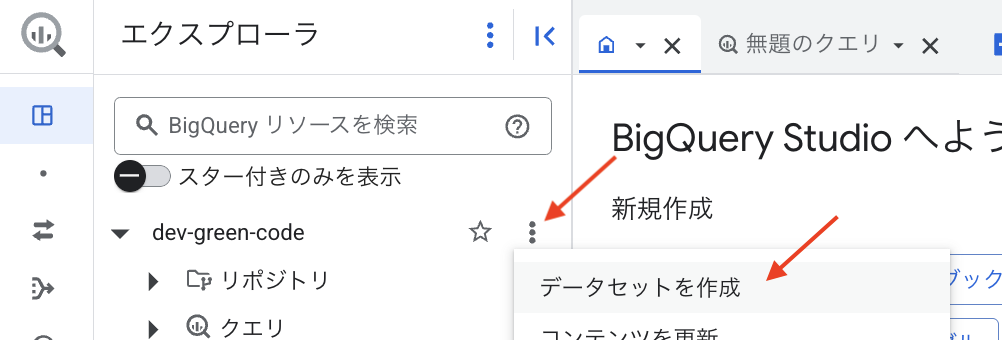
BigQuery コンソールにて、プロジェクト名の横にあるケバブメニュー(三点アイコン)から「データセットを作成」を選択します。
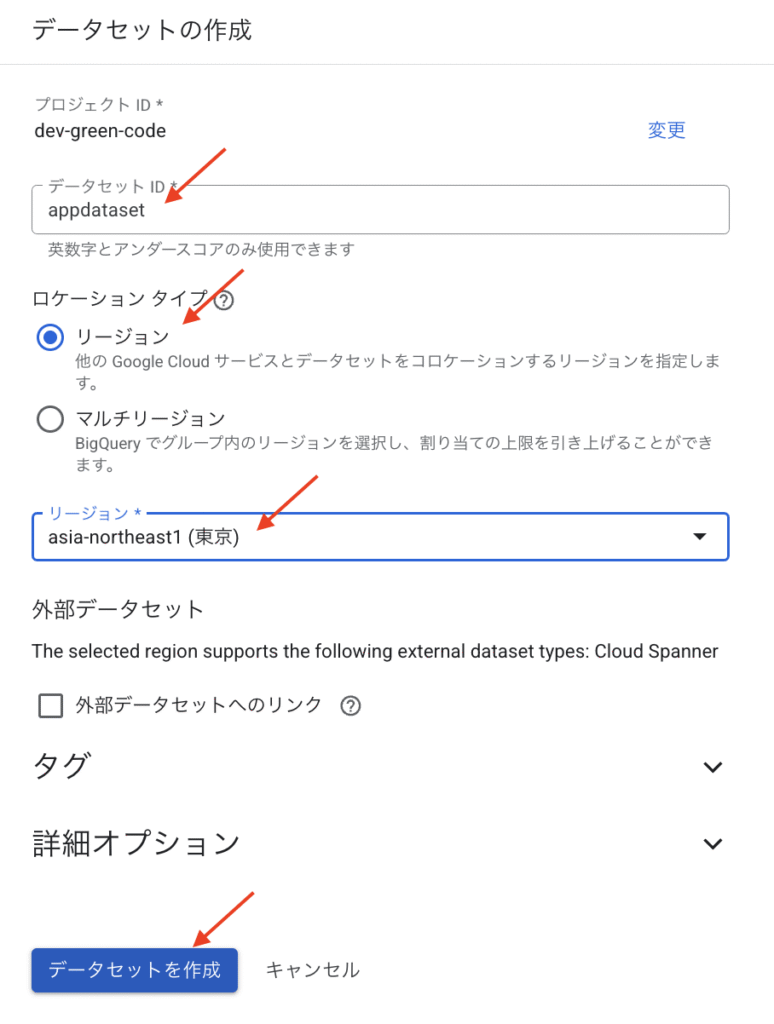
データセットに必要な情報を入力します。今回は、appdataset とリージョン東京を指定しました。
※後から知ったのですが、データセットIDにはアンダースコア(_)も使えるので、単語の区切りに利用すると読みやすくなります。
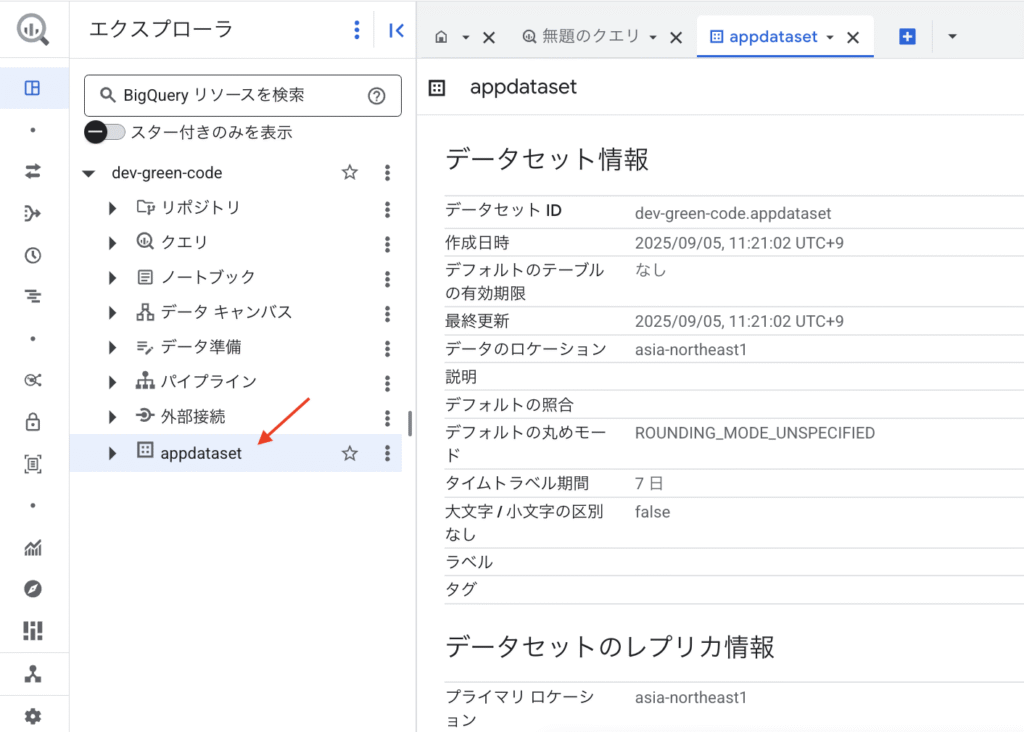
作成が終わると、メニューにデータセットが表示され、クリックすると詳細が確認できます。
3. テーブル作成
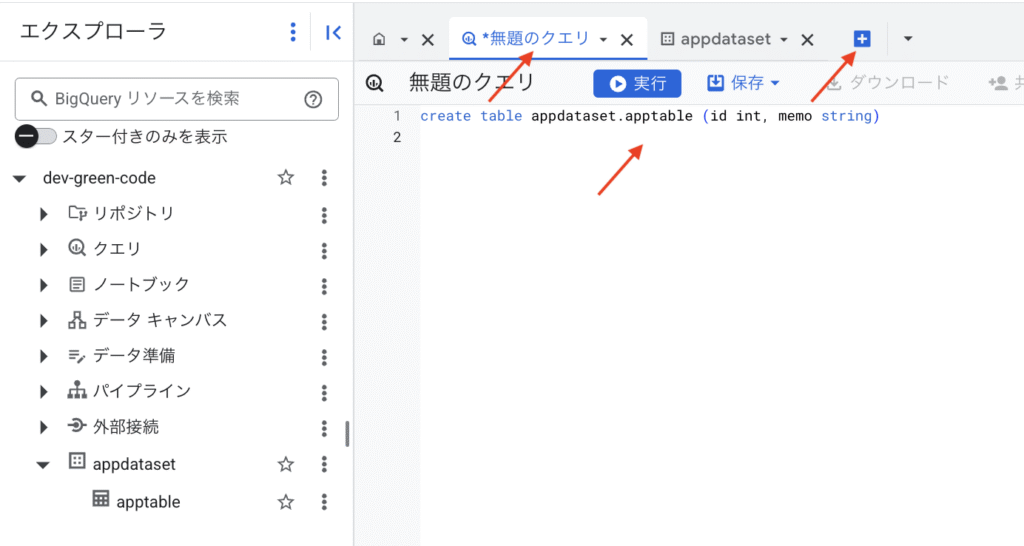
無題のクエリータブを開いて、以下のようなDDL を実行してテーブルを作成します。
create table appdataset.apptable (id int, memo string)BigQuery の DDL は PostgreSQL などと非常に似ているため、SQL に慣れていれば迷わず操作できると思います。
「無題のクエリ」というタブを選ぶか、「+」を押すとクエリーを発行できます。実行を押すとテーブルが作成されます。
4. サービスアカウントの作成
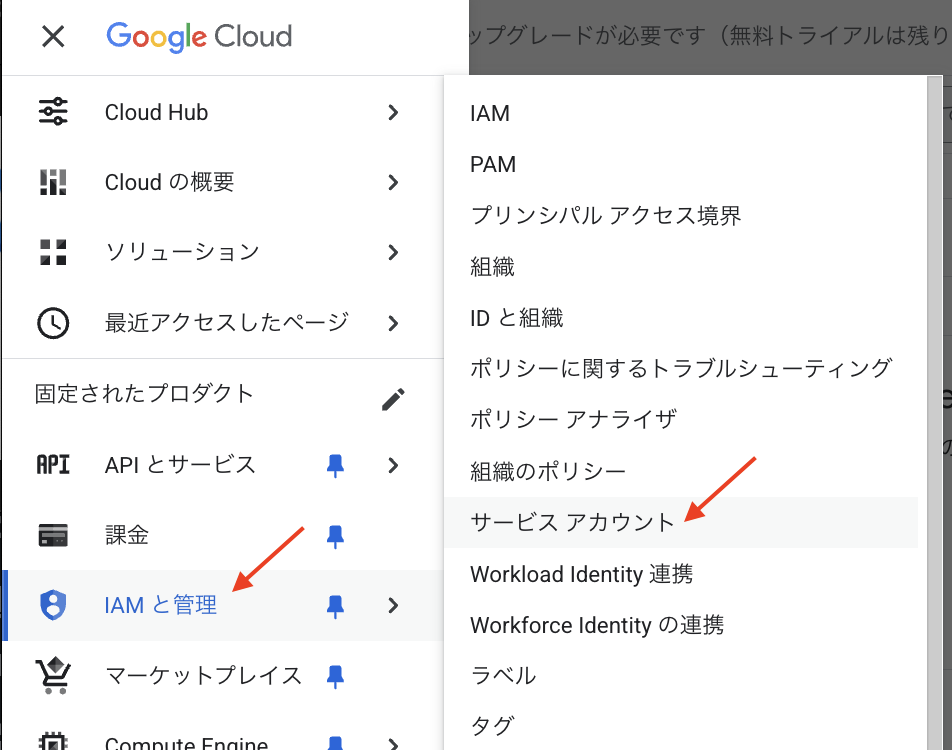
次に、Java から BigQuery にアクセスするための認証情報を設定します。
「IAMと管理」 > 「サービスアカウント」を選択します。
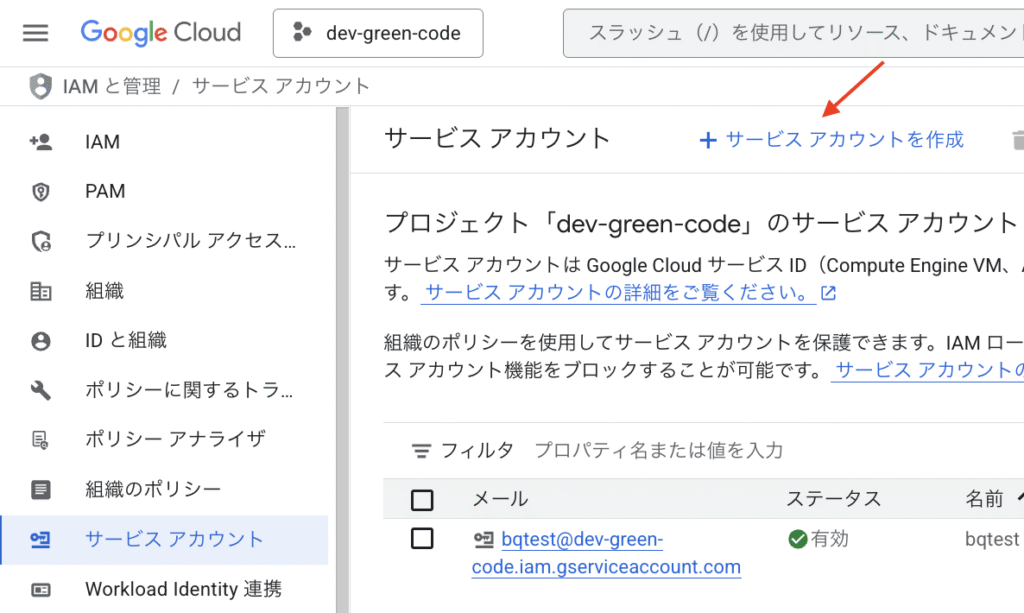
「+サービスアカウントを作成」をクリック
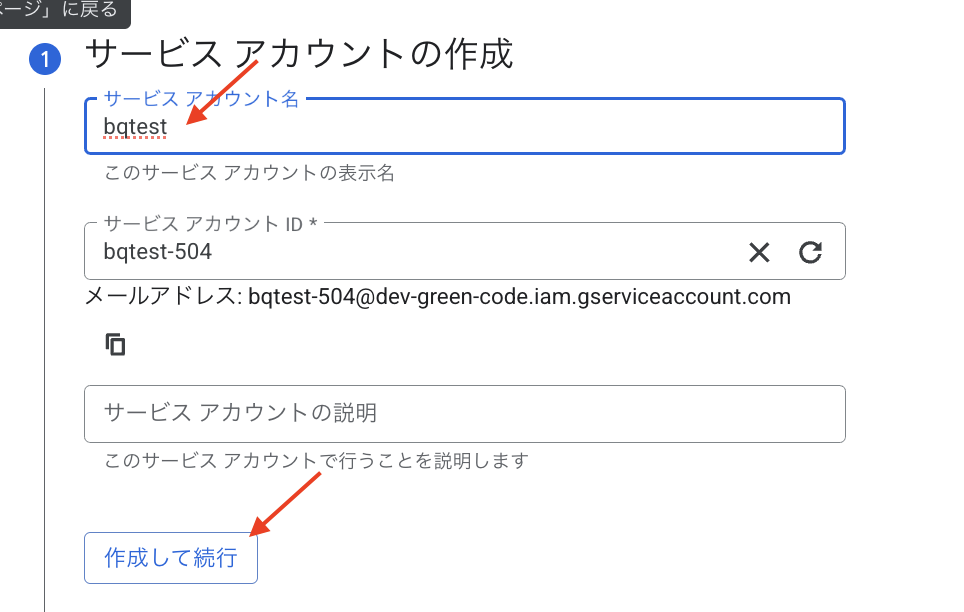
お好きなサービスアカウント名を入力します。今回は「bqtest」としました。
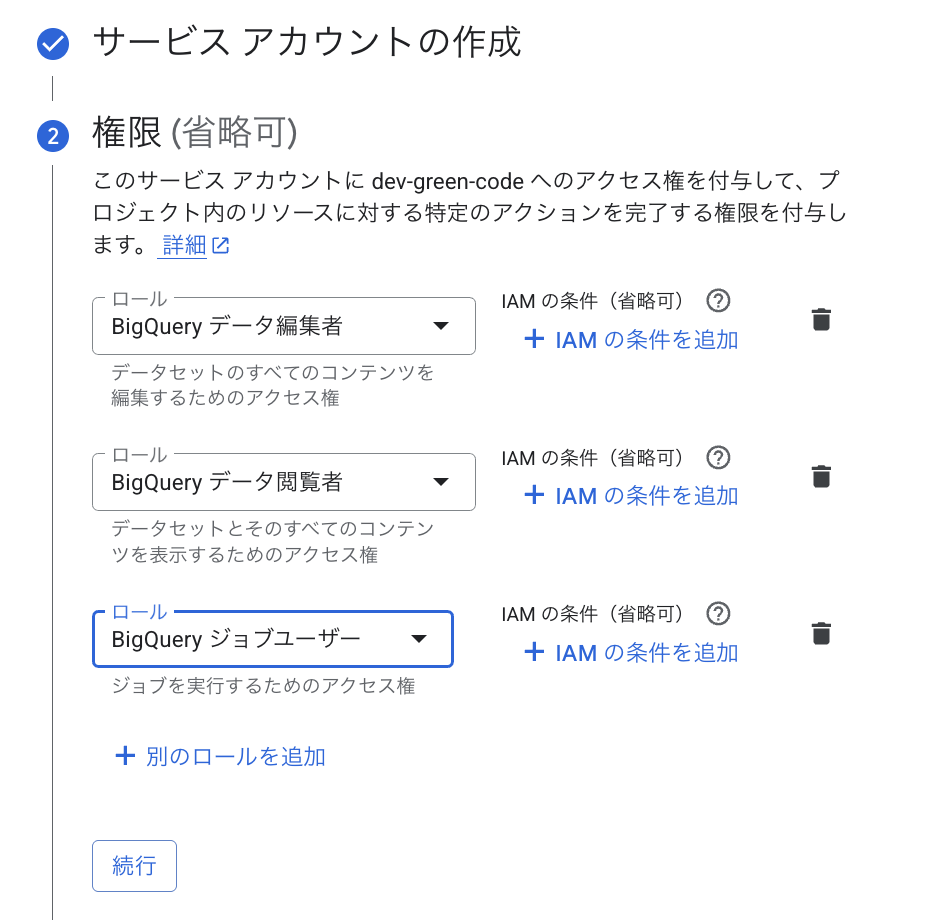
権限を設定します。最低限必要な権限は以下の通りです。
データ挿入のみ BigQuery データ編集者クエリ実行も行う場合 BigQuery データ閲覧者BigQuery ジョブユーザー
アクセス権を持つプリンシパルは省略しました。
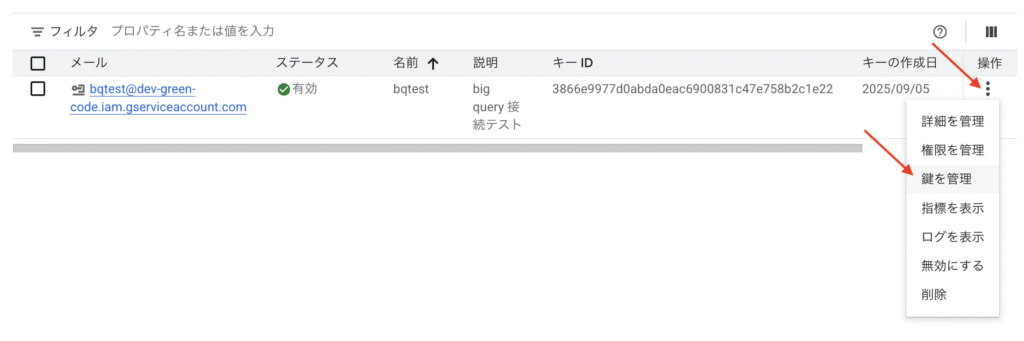
アカウント作成後は鍵の作成を行います。操作にあるケバブメニューから「鍵を管理」を選びます。
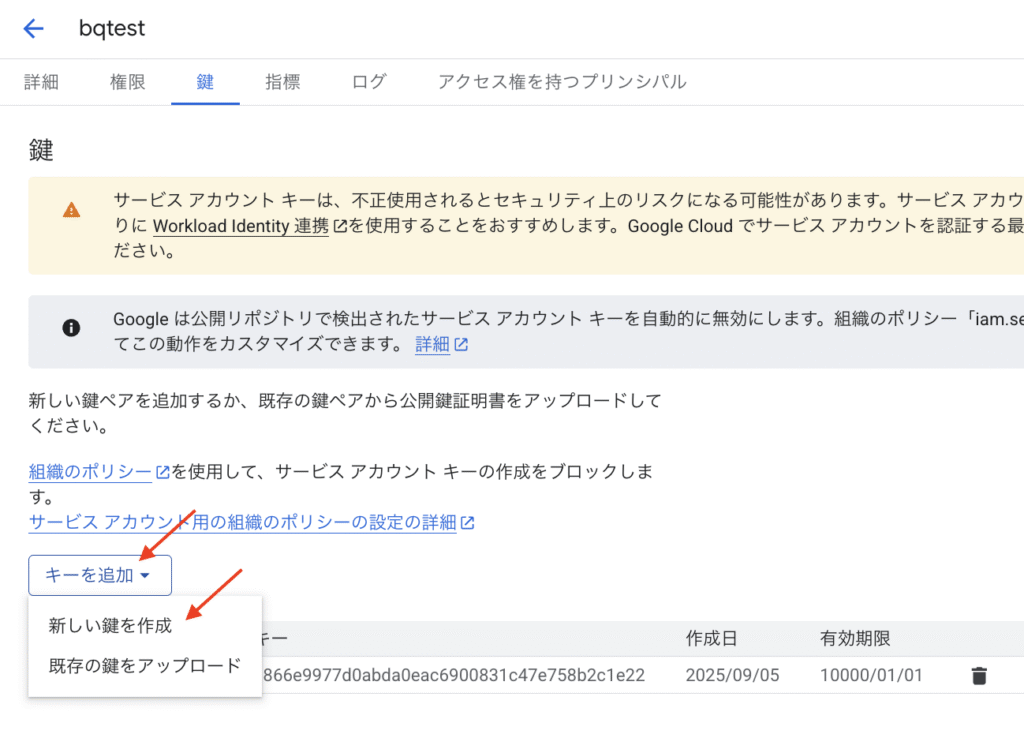
「キーを追加」> 「新しい鍵を作成」を選択します。
タイプをJSON にして作成すると、JSON ファイルがダウンロードされます。
この JSON ファイルは後ほど Java コードの環境変数で使用するので、安全な場所に保管し、ファイルパスを控えておいてください。
5. Java からデータ挿入
依存ライブラリをgradle (or maven) に追加します。
implementation("com.google.cloud:google-cloud-bigquery:2.54.2")このようなjava コードを書きます。
package org.example;
import com.google.cloud.bigquery.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws Exception {
// BigQuery クライアントの作成
BigQuery bigquery = BigQueryOptions.getDefaultInstance().getService();
// テーブル参照
TableId tableId = TableId.of("appdataset", "apptable");
// 挿入する行データの定義(カラム名と値のペア)
Map<String, Object> rowContent = new HashMap<>();
rowContent.put("id", new Date().getTime());
rowContent.put("memo", new Date().toString());
// RowToInsert オブジェクトを作成
InsertAllRequest.RowToInsert row = InsertAllRequest.RowToInsert.of(rowContent);
// 挿入リクエストの作成
InsertAllResponse response = bigquery.insertAll(
InsertAllRequest.newBuilder(tableId)
.addRow(row)
.build()
);
// エラーハンドリング
if (response.hasErrors()) {
System.out.println("エラーが発生しました:");
response.getInsertErrors().forEach((key, err) -> System.out.println(err));
} else {
System.out.println("データを正常に挿入しました。");
}
}
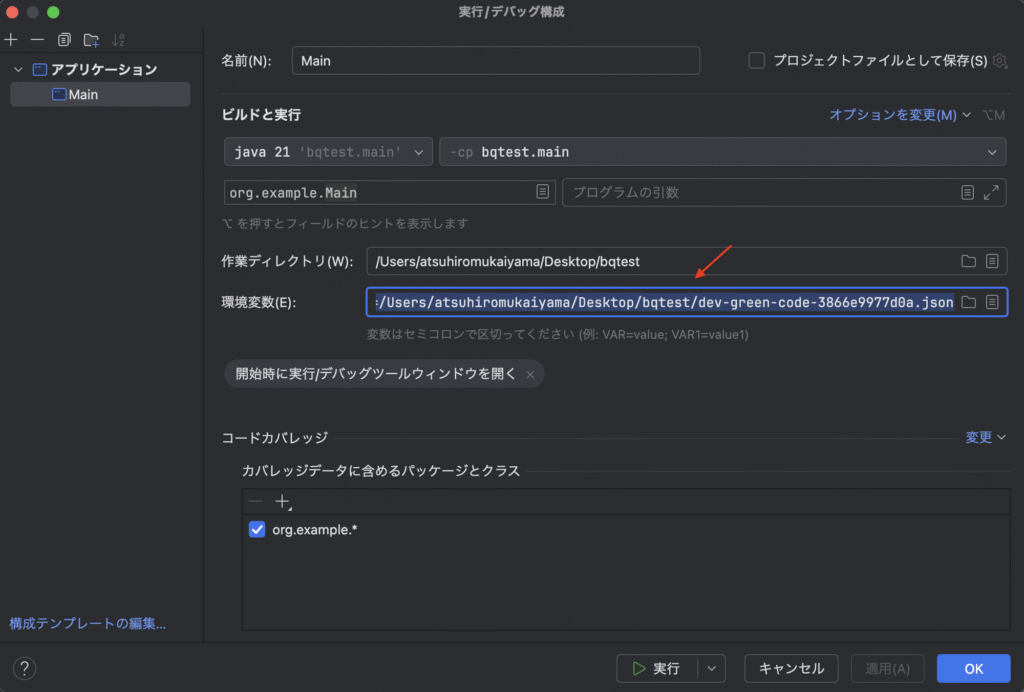
}このプログラムを実行する際、環境変数に先ほどダウンロードしたJSONファイルのパスを指定する必要があります。
GOOGLE_APPLICATION_CREDENTIALS=/opt/testpj-3866e9977d0a.jsonintelliJ を使っている場合は、構成の編集から環境変数を指定できます。
まとめ
一連のセットアップが完了すれば、Java からBigQuery へデータ挿入するのはとてもスムーズでした。
JDBC での操作とほとんど変わらない印象です。
【広告】