iPhoneのメモアプリは、私にとって非常に使いやすく優れたツールです。その中でも、特に気に入っているのが 複数デバイス間での自動同期機能 です。
この機能のおかげで、メモを取るときにネット接続がなくても構いません。ネットに接続されたタイミングで、自動的に他のデバイスに同期されるからです。しかも、ユーザーが意識して操作をすることなく、「気づいたら同期されている」 という自然な使い心地が実現されています。
同期とマージの難しさ
このような便利な機能を、自分のアプリでも再現できないかと考えています。
「ネットに再接続されたタイミングでバックアップ処理が走る」という仕組みは比較的想像しやすいのですが、問題はそのときの テキストのマージ処理 です。
プログラマーであればお分かりかと思いますが、これは Git のマージコンフリクトの解消に近い処理になります。複数の編集が同じ場所で衝突したとき、どちらの内容を優先するか、あるいはどう統合するかを決めなければなりません。
実際にiPhoneのメモアプリで試してみた
挙動を確認するため、iPhoneとMacBookでそれぞれ同じメモを別々に編集し、同期がどのように行われるかを検証してみました。
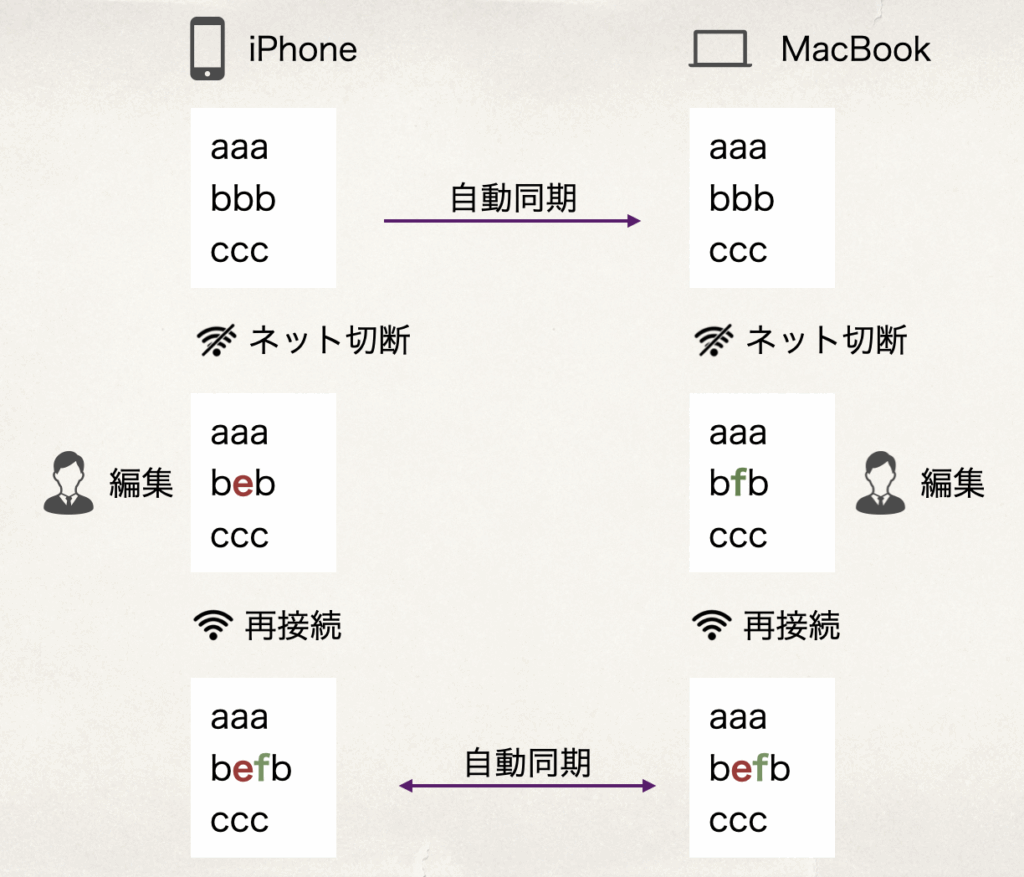
なんと、両方の修正が取り込まれている結果になりました。
これはメモアプリとして非常に良い挙動と思います。どちらか一方の編集だけが残り、もう一方の内容が失われてしまうと、ユーザーにとっては大切な情報の欠落するかもしれません。欠落するより、両方の修正が残った方がユーザにとっては嬉しいはずです。
Gitで同じことが起きたら?
先述の通り、通常はコンフリクト解消作業が必要となります。
たとえば以下のように、ブランチ毎に修正内容が列挙されるので、開発者が差分を確認しながらマージ作業を行わなければなりません。この作業って大変ですよね。
<<<<<<< HEAD
beb
=======
bfb
>>>>>>> feature-branch技術的解決の方向性
差分の算出には JavaDiffUtils という優れたライブラリがありました。これを使えば、2つのテキスト間の差分抽出は完璧に行えます。さらに、3-way-merge(3者間マージ) という手法を使うことで、編集前・編集1・編集2の3つのバージョンを比較して、よりスマートなマージが可能になります。
現在、プロトタイプを作成しています。近いうちに記事として公開予定なので、興味のある方はチェックしていただけると嬉しいです。
アイコンを使わせていただきました。素敵なアイコンをありがとうございます。
https://icooon-mono.com
Offline icons created by NajmunNahar – Flaticon
Internet-connection icons created by NajmunNahar – Flaticon
【広告】